Sự khác biệt giữa AI vs Học máy vs Học sâu vs Mạng nơ-ron nhân tạo
Ngày nay, công nghệ đang đi sâu vào cuộc sống của chúng ta hơn bao giờ hết. Chúng ta có thể thấy chúng ở khắp mọi nơi trên phương tiện truyền thông xã hội hoặc ứng dụng trên điện thoại của bạn, v.v. Những thứ này làm cho trải nghiệm của chúng ta tốt hơn. Và để bắt kịp tốc độ mong đợi của người dùng, các công ty cũng đang cố gắng áp dụng ngày càng nhiều công nghệ liên quan đến trí tuệ nhân tạo (AI), học máy (Machine Leanring), học sâu (Deep Learning) và mạng nơ-ron nhân tạo (Neural Networks).
Những thuật ngữ này thường được sử dụng trong các cuộc trò chuyện của chúng ta, nhưng sự khác biệt giữa chúng là gì? Trong bài viết này, hãy cùng làm rõ điều đó nhé.
Trí tuệ nhân tạo, học máy, mạng nơ-ron nhân tạo và học sâu có mối quan hệ như thế nào?
Có lẽ cách dễ nhất để phân biệt trí tuệ nhân tạo, học máy, mạng nơ-ron nhân tạo và học sâu là nghĩ về chúng như những con búp bê xếp chồng của Nga. Về cơ bản là mỗi thuật ngữ này là một thành phần của thuật ngữ trước.
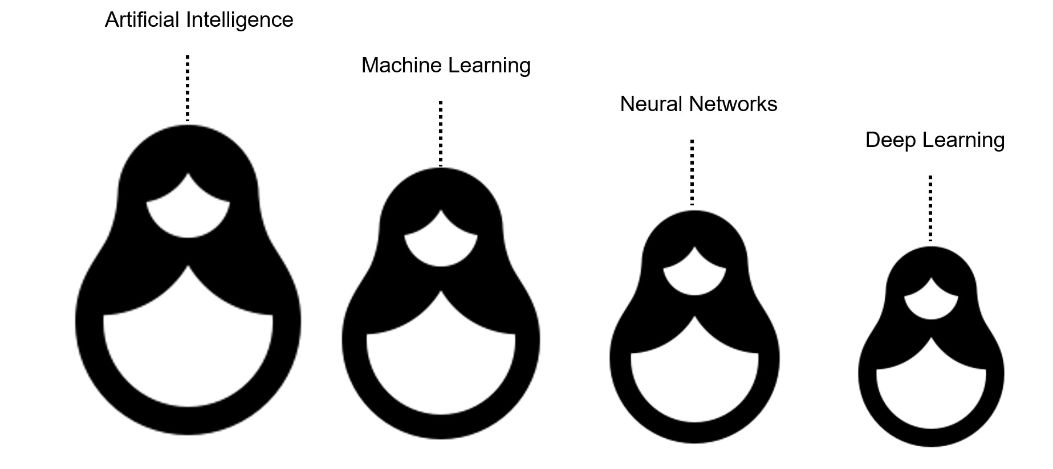
Có thể hiểu là, học máy là một lĩnh vực con của trí tuệ nhân tạo. Học sâu là một lĩnh vực con của học máy và mạng nơ-ron nhân tạo tạo nên xương sống của các thuật toán học sâu. Trên thực tế, chính số lượng lớp node, hay độ sâu, của mạng nơ-ron nhân tạo giúp phân biệt một mạng nơ-ron đơn lẻ với một thuật toán học sâu, vốn phải có nhiều hơn ba.
Mạng nơron nhân tạo là gì?
Mạng nơ-ron (neural networks) – hay cụ thể hơn là mạng nơ-ron nhân tạo (artificial neural networks ANNs) – bắt chước bộ não con người thông qua một tập hợp các thuật toán. Ở cấp độ cơ bản, mạng nơ-ron có bốn thành phần chính: đầu vào (inputs), weights, bias hoặc threshold và đầu ra (outputs). Tương tự như hồi quy tuyến tính (linear regression), công thức đại số sẽ giống như sau:
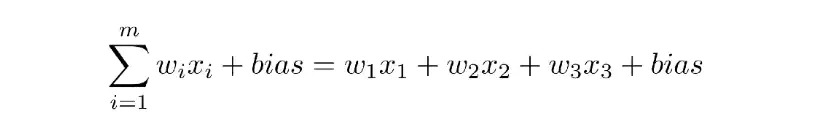
Từ đó, ta áp dụng nó vào một ví dụ, chẳng hạn như bạn có nên gọi một chiếc pizza cho bữa tối hay không. Đây sẽ là kết quả dự đoán, hoặc y-hat. Giả sử rằng quyết định của bạn sẽ bị ảnh hưởng bởi ba yếu tố chính như sau:
-
-
-
- Nếu bạn sẽ tiết kiệm thời gian bằng cách đặt hàng ngoài (Có: 1; Không: 0)
- Nếu bạn muốn giảm cân bằng cách đặt một chiếc pizza (Có: 1; Không: 0)
- Nếu bạn tiết kiệm tiền (Có: 1; Không: 0)
-
-
Sau đó, giả sử những yếu tố đó, cung cấp các thông tin đầu vào sau:
-
-
-
- X1 = 1, vì bạn không nấu bữa tối
- X2 = 0, vì chúng ta nhận được TẤT CẢ các phần toppings
- X3 = 1, vì chúng ta chỉ nhận được 2 phần
-
-
Đầu vào sẽ có giá trị nhị phân 0 hoặc 1 để đơn giản hóa. Về mặt kỹ thuật, điều này định nghĩa nó là một perceptron vì mạng nơ-ron chủ yếu tận dụng các nơ-ron sigmoid, biểu thị các giá trị từ âm vô cùng đến dương vô cùng. Sự phân biệt này rất quan trọng bởi vì hầu hết các bài toán trong thế giới thực là phi tuyến tính, vì vậy chúng ta cần các giá trị làm giảm mức độ ảnh hưởng đến kết quả của bất kỳ đầu vào đơn lẻ nào. Tuy nhiên, tóm tắt theo cách này sẽ giúp bạn hiểu toán học cơ bản ở đây.
Bây giờ chúng ta cần gán một số weights vào để xác định mức độ quan trọng. Weights lớn hơn có nghĩa là đóng góp của đầu vào này cho đầu ra đáng kể hơn so với các đầu vào khác.
-
-
-
- W1 = 5, vì bạn coi trọng thời gian
- W2 = 3, vì bạn coi trọng việc duy trì vóc dáng
- W3 = 2, vì bạn có tiền trong ngân hàng
-
-
Cuối cùng, chúng ta cũng sẽ giả định giá trị threshold là 5, giá trị này sẽ chuyển thành giá trị bias là –5.
Vì chúng ta đã thiết lập tất cả các giá trị liên quan cho tổng kết, nên bây giờ có thể đưa chúng vào công thức này.
Sử dụng hàm kích hoạt sau, giờ đây chúng ta có thể tính toán đầu ra (tức là quyết định đặt pizza):
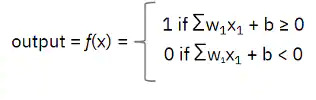
Tóm tắt:
Y-hat (kết quả dự đoán) = Quyết định đặt pizza hay không
Y-hat = (1 * 5) + (0 * 3) + (1 * 2) – 5
Y-hat = 5 + 0 + 2 – 5
Y-hat = 2, lớn hơn 0.
Vì Y-hat bằng 2, đầu ra từ hàm kích hoạt sẽ là 1, nghĩa là chúng ta sẽ đặt bánh pizza.
Nếu đầu ra của bất kỳ node riêng lẻ nào cao hơn giá trị threshold được chỉ định, node đó sẽ được kích hoạt và dữ liệu sẽ được gửi đến lớp tiếp theo của mạng. Nếu không, không có dữ liệu nào được chuyển đến lớp tiếp theo của mạng. Bây giờ, hãy tưởng tượng quá trình trên được lặp lại nhiều lần cho một quyết định duy nhất vì mạng nơ-ron có xu hướng có nhiều lớp “ẩn” như một phần của các thuật toán học sâu. Mỗi lớp ẩn có hàm kích hoạt riêng, có khả năng truyền thông tin từ lớp trước sang lớp tiếp theo. Khi tất cả các đầu ra từ các lớp ẩn được tạo ra, thì chúng được sử dụng làm đầu vào để tính toán đầu ra cuối cùng của mạng nơ-ron. Ví dụ trên chỉ là ví dụ cơ bản nhất về mạng nơ-ron; hầu hết các ví dụ trong thế giới thực là phi tuyến tính và phức tạp hơn nhiều.
Sự khác biệt chính giữa hồi quy và mạng nơ-ron là tác động của thay đổi trên một weight duy nhất. Trong hồi quy, bạn có thể thay đổi weight mà không ảnh hưởng đến các đầu vào khác trong một hàm. Tuy nhiên, trường hợp này khác với mạng nơ-ron. Vì đầu ra của một lớp này được chuyển vào lớp tiếp theo của mạng, nên một thay đổi duy nhất có thể có tác động phân tầng lên các nơ-ron khác trong mạng.
Học sâu khác với mạng nơ-ron như thế nào?
Trên thực tế, học sâu được ngụ ý trong phần giải thích của mạng nơ-ron. Chữ “sâu” trong học sâu là đề cập đến độ sâu của các lớp trong mạng nơ-ron. Một mạng nơ-ron bao gồm hơn ba lớp — sẽ bao gồm đầu vào và đầu ra — có thể được coi là một thuật toán học sâu. Điều này thường được biểu diễn bằng sơ đồ sau:
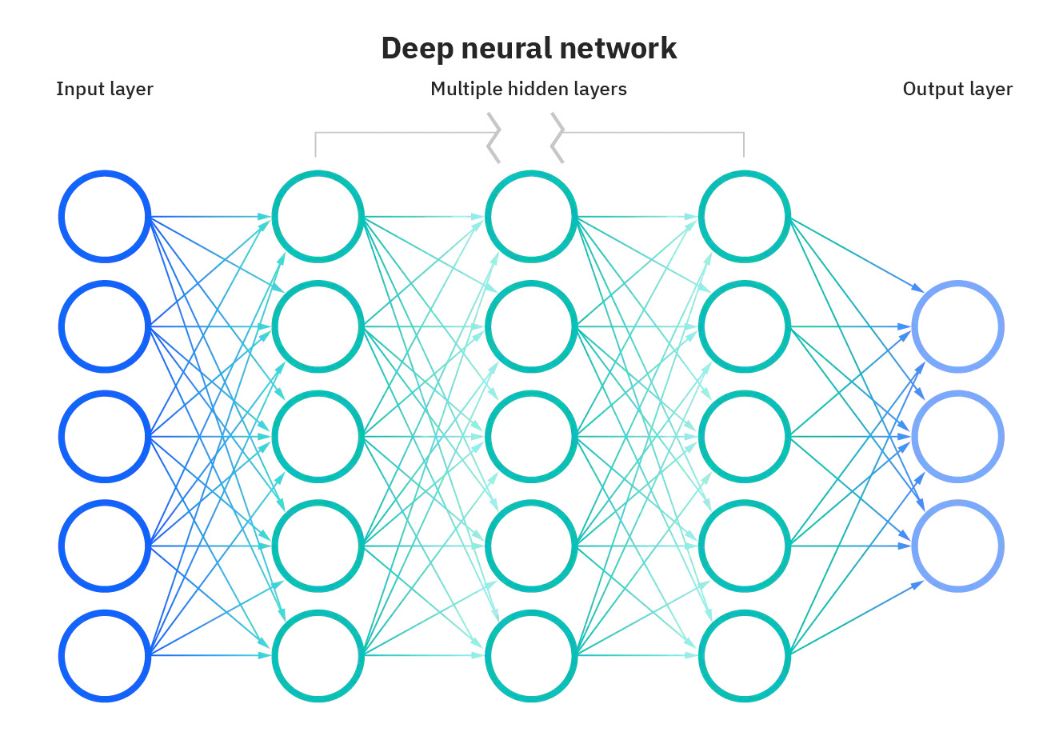
Hầu hết các mạng nơ-ron sâu đều chuyển tiếp (feed-forward), có nghĩa là chúng chỉ chạy theo một hướng từ đầu vào đến đầu ra. Tuy nhiên, bạn cũng có thể đào tạo mô hình của mình theo hướng ngược lại từ đầu ra đến đầu vào và nó được gọi là truyền ngược (backpropagation). Truyền ngược cho phép chúng ta tính toán và quy lỗi liên quan đến từng nơ-ron, cho phép điều chỉnh thuật toán một cách thích hợp.
Học sâu khác với học máy như thế nào?
Học sâu có thể được hiểu đơn thuần là một tập hợp con của học máy. Sự khác biệt chính là cách mà mỗi thuật toán học và lượng dữ liệu mà mỗi loại thuật toán sử dụng. Học sâu tự động hóa phần lớn phần trích xuất tính năng của quy trình, loại bỏ một số sự can thiệp thủ công của con người. Nó cũng cho phép sử dụng các tập dữ liệu lớn. Khả năng này sẽ đặc biệt thú vị khi chúng ta bắt đầu khám phá việc sử dụng dữ liệu phi cấu trúc nhiều hơn, đặc biệt vì 80-90% dữ liệu của một tổ chức được ước tính là không có cấu trúc.
Học máy cổ điển, hoặc “không sâu”, phụ thuộc nhiều hơn vào sự can thiệp của con người để học. Các chuyên gia con người xác định thứ bậc của các tính năng để hiểu sự khác biệt giữa các đầu vào dữ liệu, thường yêu cầu nhiều dữ liệu có cấu trúc hơn để tìm hiểu.
Học máy “sâu” có thể tận dụng tập dữ liệu được gắn nhãn, còn được gọi là học có giám sát, để thông báo cho thuật toán của nó, nhưng không nhất thiết phải yêu cầu tập dữ liệu được gắn nhãn. Nó có thể nhập dữ liệu phi cấu trúc ở dạng thô (ví dụ: văn bản, hình ảnh) và nó có thể tự động xác định tập hợp các tính năng giúp phân biệt thứ này với thứ kia.
Bằng cách quan sát các mẫu trong dữ liệu, mô hình học sâu có thể phân cụm đầu vào một cách thích hợp. Chúng ta có thể nhóm các hình ảnh của các mục khác nhau thành các danh mục tương ứng của chúng dựa trên những điểm tương đồng hoặc khác biệt được xác định trong hình ảnh. Như đã nói, mô hình học sâu sẽ yêu cầu nhiều điểm dữ liệu hơn để cải thiện độ chính xác của nó, trong khi mô hình học máy dựa trên ít dữ liệu hơn với cấu trúc dữ liệu cơ bản. Học sâu chủ yếu được sử dụng cho các trường hợp sử dụng phức tạp hơn, như trợ lý ảo hoặc phát hiện gian lận.
Trí tuệ nhân tạo (AI) là gì?
Cuối cùng, trí tuệ nhân tạo (AI) là thuật ngữ rộng nhất được sử dụng để phân loại các loại máy móc bắt chước trí thông minh của con người. Nó được sử dụng để dự đoán, tự động hóa và tối ưu hóa các tác vụ mà con người đã thực hiện trong lịch sử, chẳng hạn như nhận dạng giọng nói và khuôn mặt, ra quyết định và dịch thuật.
Có ba loại AI chính:
-
-
-
- Artificial Narrow Intelligence (ANI)
- Artificial General Intelligence (AGI)
- Artificial Super Intelligence (ASI)
-
-
ANI được coi là AI “yếu”, trong khi hai loại còn lại được phân loại là AI “mạnh”. AI yếu được định nghĩa bằng khả năng hoàn thành một nhiệm vụ rất cụ thể, chẳng hạn như thắng một ván cờ vua hoặc xác định một cá nhân cụ thể trong một loạt ảnh. AGI và ASI là dạng AI mạnh hơn và chúng kết hợp nhiều hành vi của con người hơn, chẳng hạn như khả năng diễn giải giọng điệu và cảm xúc.
AI mạnh được định nghĩa bởi khả năng của nó so với con người. Artificial General Intelligence (AGI) sẽ hoạt động ngang bằng với một con người khác trong khi Artificial Super Intelligence (ASI) – còn được gọi là siêu trí tuệ – sẽ vượt qua trí thông minh và khả năng của con người. Cả hai dạng AI mạnh đều chưa tồn tại, nhưng các nghiên cứu trong lĩnh vực này vẫn được tiếp tục.
Kết luận
iRender hiện đang cung cấp GPU Cloud cho dịch vụ AI/ DL để người dùng có thể đào tạo các mô hình của họ. Với các máy cấu hình và hiệu suất cao (RTX3090) của chúng tôi, bạn có thể cài đặt bất kỳ phần mềm nào cần thiết cho nhu cầu của mình. Chỉ cần một vài cú nhấp chuột, bạn đã có thể truy cập vào máy của chúng tôi và có toàn quyền kiểm soát. Việc đào tạo mô hình của bạn sẽ tăng tốc độ nhanh hơn gấp nhiều lần.
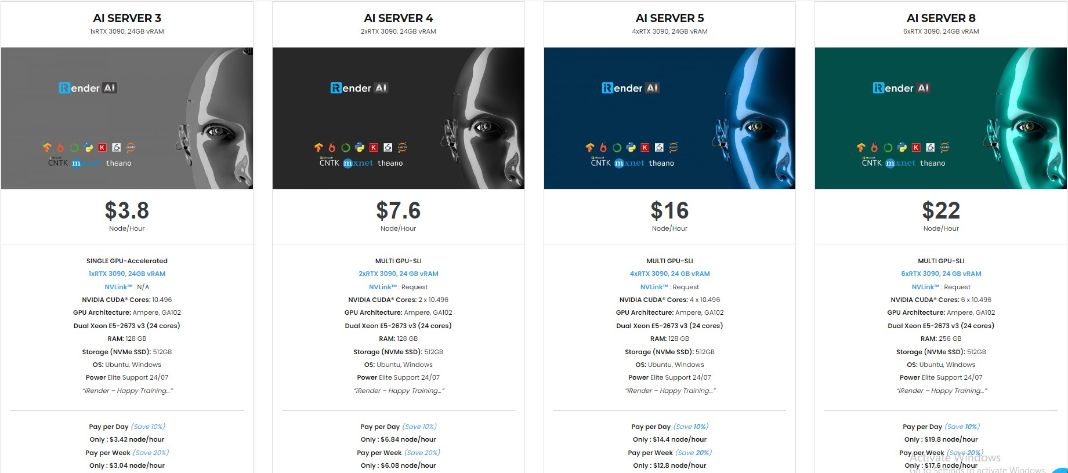
Hơn thế nữa, chúng tôi cung cấp các tính năng khác như NVLink nếu bạn cần thêm VRAM, Gpuhub Sync để truyền và đồng bộ hóa tệp nhanh hơn, tính năng Fixed Rental (thuê cố định dài hạn) để tiết kiệm tiền từ 10-20% so với thuê theo giờ (10% cho thuê hàng ngày, 20% cho thuê hàng tuần và hàng tháng).
Đăng ký tài khoản ngay hôm nay để trải nghiệm dịch vụ của chúng tôi. Hoặc liên hệ với chúng tôi qua Zalo 0916806116 để được tư vấn và hỗ trợ.
Cảm ơn bạn & Happy training!
Nguồn: ibm.com