RTX3090 có phải GPU tốt nhất cho Deep Learning không?
Deep learning – Học sâu là một lĩnh vực đòi hỏi tính toán cao và giai đoạn training là giai đoạn cần rất nhiều thời gian và nguồn lực. Ví dụ nếu số lượng các tham số của bạn tăng lên, thời gian training của bạn sẽ lâu hơn. Điều đó có nghĩa là tài nguyên của bạn đang được sử dụng lâu hơn và bạn sẽ phải chờ đợi và lãng phí thời gian quý báu của mình.
Các GPUs có thể giúp giảm các chi phí này vì chúng giúp bạn chạy các tác vụ training của mình song song, phân phối tác vụ trên các cụm bộ xử lý và thực hiện các hoạt động tính toán đồng thời. Do đó, bạn có thể chạy nhanh chóng và hiệu quả các mô hình có số lượng thông số lớn.
Hôm nay, hãy cùng xem so sánh từ bizon-tech.com về hiệu suất của ba GPU, là các phiên bản mới nhất của dòng card 30 – RTX 3090, RTX 3080 và RTX 3070 của NVIDIA. Chúng đã trở thành những card đồ họa phổ biến và được săn lùng nhiều nhất cho học sâu vào năm 2021, vì họ đã nâng cấp rất nhiều từ dòng 20-series của NVIDIA, được phát hành vào năm 2018.
Trong bài viết này hãy cùng iRender tìm hiểu về đâu là GPU tốt nhất cho Deep Learning bạn nhé!
Cách thức thực hiện
-
-
-
- Sử dụng benchmark tiêu chuẩn của TensorFlow “py” từ trang chính của GitHub (tham khảo ở đây để biết thêm chi tiết).
- Chạy kiểm tra trên các mạng sau: ResNet-50, ResNet-152, Inception v3, Inception v4, VGG-16.
- So sánh hiệu suất FP16 với FP32 và kích thước batch tiêu chuẩn được sử dụng (64, trong hầu hết các trường hợp).
- So sánh tỷ lệ GPU trên tất cả các GPU dòng 30 lên đến 2x GPU và trên A6000 lên đến 4x GPU!
-
-
Để so sánh chính xác dữ liệu benchmark từ nhiều máy trạm, đội nhóm của Bizon-tech đã duy trì tính nhất quán bằng cách cài đặt cùng một phiên bản driver và framework trên mỗi máy trạm. Điều quan trọng là phải giữ một môi trường được kiểm soát để có dữ liệu hợp lệ, có thể so sánh được.
Phần cứng
Đội nhóm của Bizon-tech đã sử dụng 2 máy trạm cho bài test này để tìm ra GPU tốt nhất cho Deep Learning.
Máy đầu tiên:
-
-
-
- CPU: Intel Core i9-10980XE 18-Core 3,00 GHz
- Ép xung: bước#3 +600 MHz (hiệu suất lên đến + 30%)
- Hệ thống làm mát: Hệ thống làm mát bằng chất lỏng (CPU; ổn định hơn và tiếng ồn thấp)
- Bộ nhớ: 256 GB (8 x 32 GB) DDR4 3200 MHz
- Hệ điều hành: BIZON Z – Stack (Ubuntu 20.04 (Bionic) với các khung học sâu được cài đặt sẵn)
- HDD: 1TB PCIe SSD
- Network: 10 GBIT
-
-
Máy thứ hai:
-
-
-
- CPU: Intel Core i9-10980XE 18-Core 3,00 GHz
- Ép xung: bước#3 +600 MHz (hiệu suất lên đến + 30%)
- Hệ thống làm mát: Hệ thống làm mát bằng nước tùy chỉnh (CPU + GPU)
- Bộ nhớ: 256 GB (8 x 32 GB) DDR4 3200 MHz
- Hệ điều hành: BIZON Z – Stack (Ubuntu 20.04 (Bionic) với các khung học sâu được cài đặt sẵn)
- HDD: 1TB PCIe SSD
- Network: 10 GBIT
-
-
Phần mềm
Mô hình học sâu:
-
-
-
- Resnet50
- Resnet152
- Inception V3
- Inception V4
- VGG16
-
-
Drivers và Batch size:
-
-
-
- Nvidia Driver: 455
- CUDA: 11.1
- TensorFlow: 1.x
- Batch size: 64
-
-
Benchmarks của GPU tốt nhất cho Deep Learning
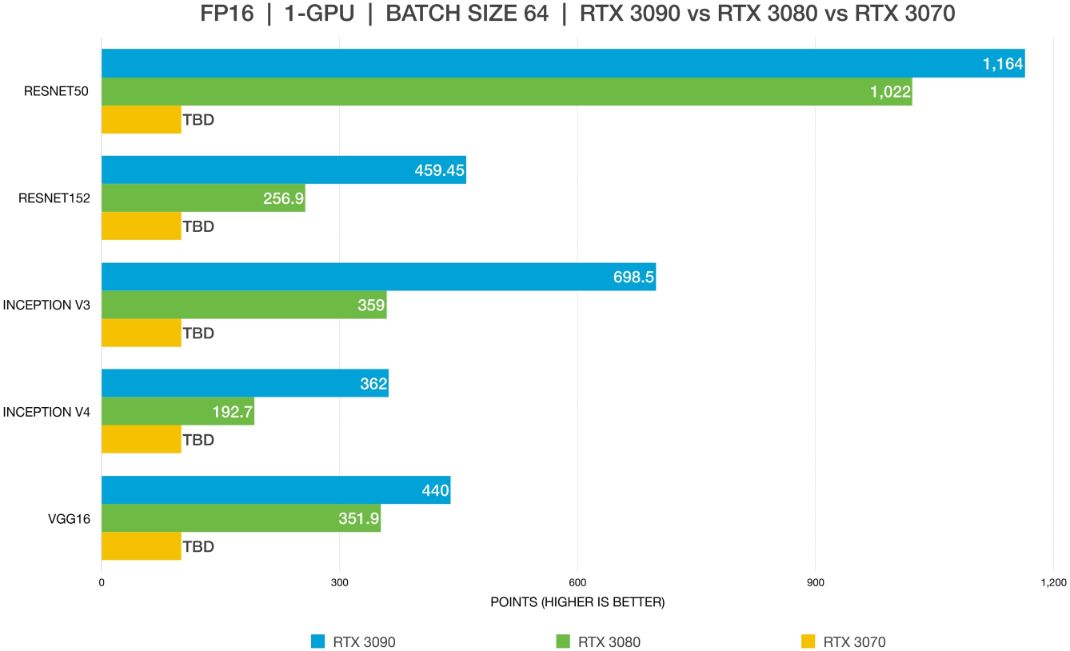
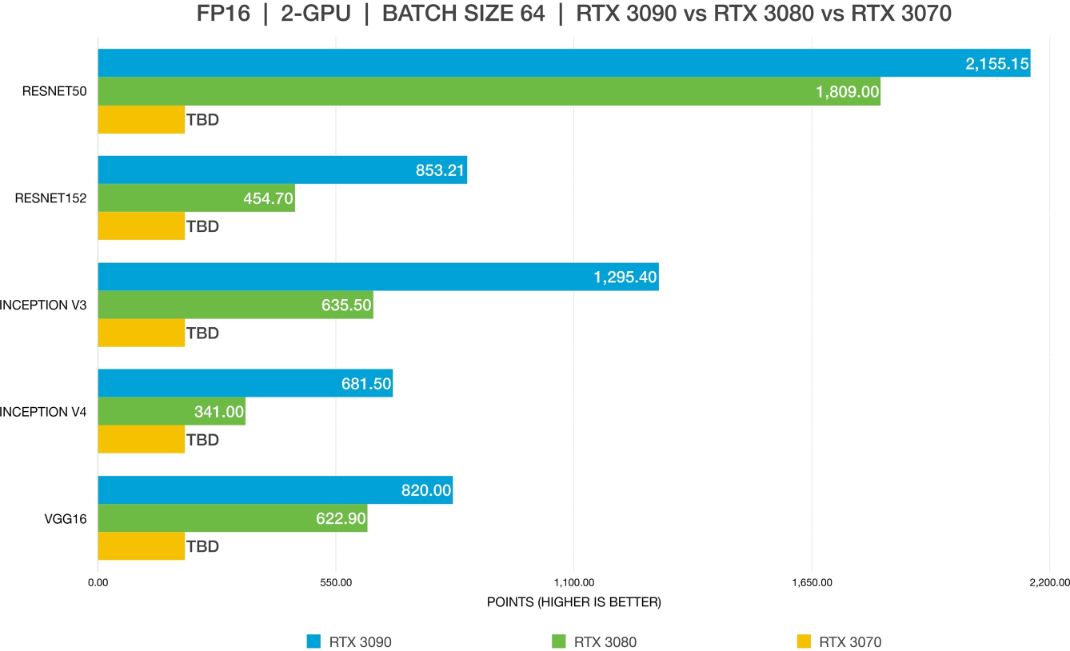


Kết luận về GPU tốt nhất cho Deep Learning
RTX 3090 là lựa chọn tốt nhất nếu bạn muốn có hiệu suất tuyệt vời. RTX 3090 là mẫu GPU duy nhất trong dòng 30 có khả năng mở rộng với NVLink. Khi được sử dụng như một cặp với cầu nối NVLink, nó sẽ có bộ nhớ 48 GB hiệu quả để train các mô hình lớn.
RTX 3080 cũng là một GPU tuyệt vời cho học sâu. Tuy nhiên, nó có một hạn chế là kích thước VRAM. Training trên RTX 3080 sẽ yêu cầu kích thước batch nhỏ, vì vậy những người có mô hình lớn hơn có thể không train được.
RTX 3070, khi so sánh với RTX3090 và RTX3080, không thực sự là một lựa chọn tốt (hiệu suất thực sự thấp). Và nó giống như RTX3080, có giới hạn về kích thước VRAM. Training trên RTX 3070 sẽ yêu cầu kích thước batch thậm chí còn nhỏ hơn 3080.
Đối với hầu hết người dùng, RTX 3090 hoặc RTX 3080 sẽ cung cấp hiệu suất tốt nhất. Hạn chế duy nhất của 3080 là kích thước VRAM 10 GB của nó. Làm việc với kích thước batch lớn cho phép các mô hình train nhanh hơn và chính xác hơn, tiết kiệm nhiều thời gian. Với thế hệ mới nhất, điều này chỉ có thể thực hiện được với card A6000 hoặc RTX 3090. Việc sử dụng FP16 cho phép các mô hình phù hợp với các GPU không đủ VRAM. Trong biểu đồ #3 và #4, RTX 3080 không thể phù hợp với các mô hình trên Resnet-152 và inception-4 sử dụng FP32. Sau khi thay đổi thành FP16, mô hình có thể phù hợp hoàn hảo. 24 GB VRAM của RTX 3090 là quá đủ cho hầu hết các trường hợp sử dụng, cho phép không gian cho hầu hết mọi kiểu máy và kích thước batch lớn.
iRender hiện đang cung cấp GPU Cloud cho dịch vụ AI/ DL để người dùng có thể đào tạo các mô hình của họ. Với các máy cấu hình và hiệu suất cao (RTX3090) của chúng tôi, bạn có thể cài đặt bất kỳ phần mềm nào cần thiết cho nhu cầu của mình. Chỉ cần một vài cú nhấp chuột, bạn đã có thể truy cập vào máy của chúng tôi và có toàn quyền kiểm soát. Việc đào tạo mô hình của bạn sẽ tăng tốc độ nhanh hơn gấp nhiều lần.
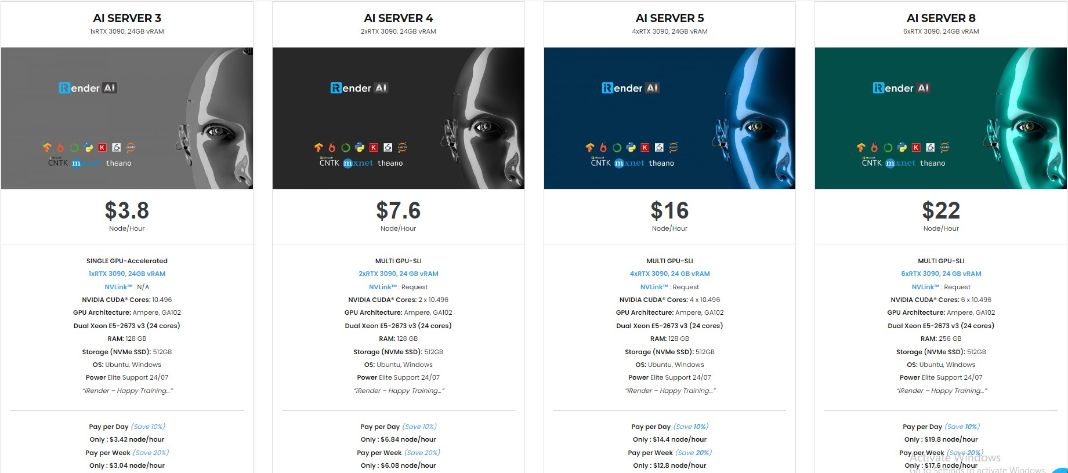
Hơn thế nữa, chúng tôi cung cấp các tính năng khác như NVLink nếu bạn cần thêm VRAM, Gpuhub Sync để truyền và đồng bộ hóa tệp nhanh hơn, tính năng Fixed Rental (thuê cố định dài hạn) để tiết kiệm tiền từ 10-20% so với thuê theo giờ (10% cho thuê hàng ngày, 20% cho thuê hàng tuần và hàng tháng).
Đăng ký tài khoản ngay hôm nay để trải nghiệm dịch vụ của chúng tôi. Hoặc liên hệ với chúng tôi qua Zalo 0916806116 để được tư vấn và hỗ trợ.
Cảm ơn bạn & Happy training!
Nguồn: bizon-tech.com