Giới thiệu về Data trong Học máy
Máy học là một dạng trí tuệ nhân tạo (AI) dạy máy tính suy nghĩ theo cách tương tự như con người: học hỏi và cải thiện dựa trên những kinh nghiệm trong quá khứ. Hầu hết mọi tác vụ có thể được hoàn thành với một mẫu hoặc bộ quy tắc do dữ liệu xác định đều có thể được tự động hóa bằng máy học. Máy học cho phép các công ty chuyển đổi các quy trình mà trước đây chỉ con người mới có thể thực hiện — hãy nghĩ đến việc trả lời các cuộc gọi dịch vụ khách hàng, ghi sổ kế toán và xem xét hồ sơ cho các doanh nghiệp hàng ngày. Máy học cũng có thể mở rộng quy mô để xử lý các vấn đề và câu hỏi kỹ thuật lớn hơn — suy nghĩ về phát hiện hình ảnh cho ô tô tự lái, dự đoán vị trí và mốc thời gian xảy ra thảm họa thiên nhiên, đồng thời hiểu được tương tác tiềm ẩn của thuốc với tình trạng y tế trước khi thử nghiệm lâm sàng. Đó là lý do tại sao học máy lại quan trọng.
Chúng ta đã đề cập đến câu hỏi “tại sao học máy lại quan trọng”, bây giờ là lúc cần hiểu vai trò của dữ liệu. Phân tích dữ liệu học máy sử dụng các thuật toán để liên tục tự cải thiện theo thời gian, nhưng dữ liệu chất lượng là cần thiết để các mô hình này hoạt động hiệu quả.
Để thực sự hiểu cách hoạt động của máy học, bạn cũng phải hiểu dữ liệu mà nó hoạt động. Hôm nay, chúng ta sẽ cùng tìm hiểu về Data trong học máy: dữ liệu học máy là gì, các loại dữ liệu cần thiết để học máy hoạt động hiệu quả.
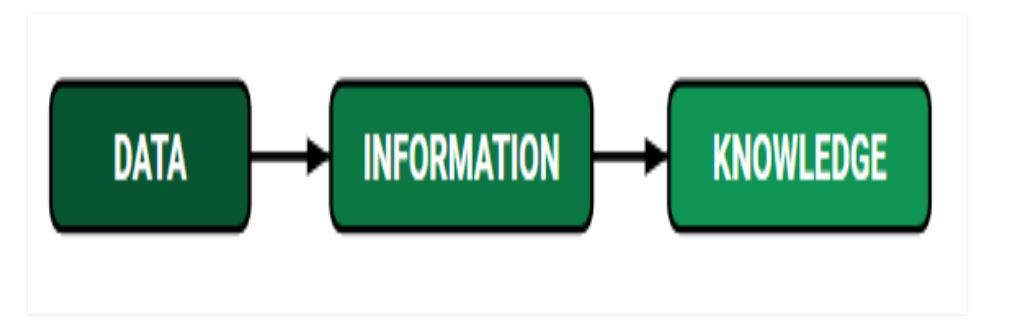
Data trong Học máy là gì?
DỮ LIỆU: Nó có thể là bất kỳ dữ kiện, giá trị, văn bản, âm thanh hoặc hình ảnh chưa được xử lý nào không được giải thích và phân tích. Dữ liệu là phần quan trọng nhất của tất cả Phân tích dữ liệu, Học máy, Trí tuệ nhân tạo. Nếu không có dữ liệu, chúng tôi không thể đào tạo bất kỳ mô hình nào và tất cả các nghiên cứu và tự động hóa hiện đại sẽ trở nên vô ích. Các Doanh nghiệp lớn đang chi rất nhiều tiền chỉ để thu thập càng nhiều dữ liệu nhất định càng tốt.
Ví dụ: Tại sao Facebook mua lại WhatsApp bằng cách trả một mức giá khổng lồ là 19 tỷ đô la?
Câu trả lời rất đơn giản và hợp lý – đó là quyền truy cập thông tin của người dùng mà Facebook có thể không có nhưng WhatsApp sẽ có. Thông tin này về người dùng của họ là vô cùng quan trọng đối với Facebook vì nó sẽ tạo điều kiện thuận lợi cho công việc cải tiến dịch vụ của họ.
THÔNG TIN: Dữ liệu đã được diễn giải và xử lý và hiện có một số suy luận có ý nghĩa cho người dùng.
KIẾN THỨC: Tổng hợp thông tin suy luận, kinh nghiệm, học tập và hiểu biết sâu sắc. Kết quả trong việc xây dựng nhận thức hoặc khái niệm cho một cá nhân hoặc tổ chức.
Máy học (machine learning) cần loại data nào?
Data có thể có nhiều dạng, nhưng các mô hình học máy dựa trên bốn kiểu dữ liệu chính. Data trong Học máy bao gồm dữ liệu số, dữ liệu phân loại, dữ liệu chuỗi thời gian và dữ liệu văn bản.
Dữ liệu số
Dữ liệu số hay dữ liệu định lượng là bất kỳ dạng dữ liệu nào có thể đo lường được như chiều cao, cân nặng hoặc chi phí hóa đơn điện thoại của bạn. Bạn có thể xác định xem một tập dữ liệu có phải là số hay không bằng cách cố gắng tính trung bình các số hoặc sắp xếp chúng theo thứ tự tăng dần hoặc giảm dần. Các số chính xác hoặc số nguyên (ví dụ: 26 học sinh trong một lớp) được coi là các số rời rạc, trong khi những số nằm trong một phạm vi nhất định (ví dụ: lãi suất 3,6 phần trăm) được coi là số liên tục. Trong khi học loại dữ liệu này, hãy nhớ rằng dữ liệu số không bị ràng buộc với bất kỳ thời điểm cụ thể nào, chúng chỉ đơn giản là các số thô.
Dữ liệu phân loại
Dữ liệu phân loại được sắp xếp theo các đặc điểm xác định. Điều này có thể bao gồm giới tính, tầng lớp xã hội, dân tộc, quê quán, ngành bạn làm việc hoặc nhiều nhãn khác. Trong khi học kiểu dữ liệu này, hãy nhớ rằng nó không phải là số, nghĩa là bạn không thể cộng chúng lại với nhau, lấy trung bình hoặc sắp xếp chúng theo bất kỳ thứ tự thời gian nào. Dữ liệu phân loại rất tuyệt vời để nhóm các cá nhân hoặc ý tưởng có chung các thuộc tính, giúp mô hình học máy của bạn hợp lý hóa việc phân tích dữ liệu.
Dữ liệu chuỗi thời gian
Dữ liệu chuỗi thời gian bao gồm các điểm dữ liệu được lập chỉ mục tại các thời điểm cụ thể. Thường xuyên hơn không, dữ liệu này được thu thập theo các khoảng thời gian nhất quán. Việc học và sử dụng dữ liệu chuỗi thời gian giúp bạn dễ dàng so sánh dữ liệu từ tuần này sang tuần khác, tháng này sang tháng khác, năm này sang năm khác hoặc theo bất kỳ số liệu dựa trên thời gian nào khác mà bạn mong muốn. Sự khác biệt rõ ràng giữa dữ liệu chuỗi thời gian và dữ liệu số là dữ liệu chuỗi thời gian đã thiết lập điểm bắt đầu và điểm kết thúc, trong khi dữ liệu số chỉ đơn giản là tập hợp các số không bắt nguồn từ các khoảng thời gian cụ thể.
Dữ liệu văn bản
Dữ liệu văn bản chỉ đơn giản là các từ, câu hoặc đoạn văn có thể cung cấp một số mức độ thông tin chi tiết về các mô hình học máy của bạn. Vì những từ này có thể khó để người mẫu tự giải thích nên chúng thường được nhóm lại với nhau hoặc phân tích bằng nhiều phương pháp khác nhau như tần suất từ, phân loại văn bản hoặc phân tích tình cảm.
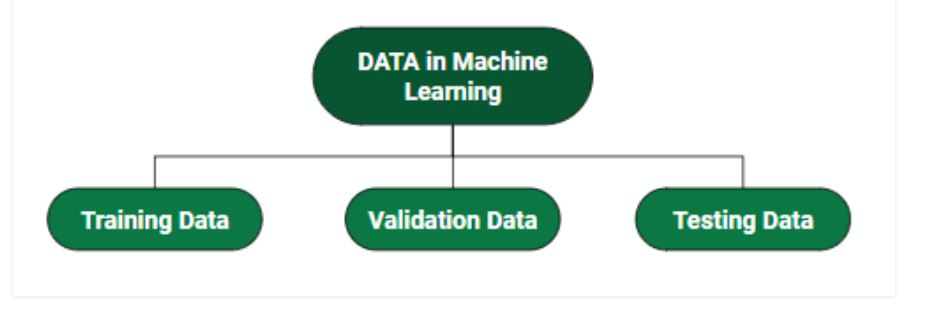
Cách phân chia Data trong Học máy?
- Dữ liệu đào tạo: Phần dữ liệu chúng tôi sử dụng để đào tạo mô hình của mình. Đây là dữ liệu mà mô hình của bạn thực sự nhìn thấy (cả đầu vào và đầu ra) và học hỏi từ đó.
- Dữ liệu xác thực: Phần dữ liệu được sử dụng để đánh giá thường xuyên mô hình, phù hợp với tập dữ liệu đào tạo cùng với việc cải thiện các siêu tham số liên quan (ban đầu đặt tham số trước khi mô hình bắt đầu học). Dữ liệu này đóng vai trò của nó khi mô hình thực sự đang được đào tạo.
- Dữ liệu thử nghiệm: Sau khi mô hình của chúng tôi được đào tạo hoàn chỉnh, dữ liệu thử nghiệm cung cấp đánh giá không thiên vị. Khi chúng tôi cung cấp đầu vào của dữ liệu Thử nghiệm, mô hình của chúng tôi sẽ dự đoán một số giá trị (mà không thấy đầu ra thực tế). Sau khi dự đoán, chúng tôi đánh giá mô hình của mình bằng cách so sánh nó với đầu ra thực tế có trong dữ liệu thử nghiệm. Đây là cách chúng tôi đánh giá và xem mô hình của chúng tôi đã học được bao nhiêu từ các kinh nghiệm được cung cấp dưới dạng dữ liệu đào tạo, được đặt tại thời điểm đào tạo.
Hãy xem xét một ví dụ:
Có một Chủ sở hữu siêu thị mua sắm đã thực hiện một cuộc khảo sát mà anh ta có một danh sách dài các câu hỏi và câu trả lời mà anh ta đã hỏi từ khách hàng, danh sách các câu hỏi và câu trả lời này là DỮ LIỆU. Giờ đây, mỗi khi anh ta muốn suy luận bất cứ điều gì và không thể chỉ lướt qua từng câu hỏi của hàng nghìn khách hàng để tìm điều gì đó có liên quan vì nó sẽ tốn thời gian và không hữu ích. Để giảm lãng phí thời gian và chi phí này và để làm cho công việc dễ dàng hơn, dữ liệu được thao tác thông qua phần mềm, tính toán, đồ thị, v.v. theo sự thuận tiện của riêng mình, suy luận từ dữ liệu được thao tác này là Thông tin. Vì vậy, Dữ liệu là yếu tố bắt buộc đối với Thông tin. Bây giờ Tri thức có vai trò của nó trong việc phân biệt giữa hai cá nhân có cùng thông tin. Kiến thức thực chất không phải là nội dung kỹ thuật mà được liên kết với quá trình tư duy của con người.
Thuộc tính của dữ liệu –
- Khối lượng: Quy mô dữ liệu. Với dân số thế giới ngày càng tăng và công nghệ được tiếp xúc, dữ liệu khổng lồ đang được tạo ra từng mili giây.
- Đa dạng: Các dạng dữ liệu khác nhau – chăm sóc sức khỏe, hình ảnh, video, đoạn âm thanh.
- Tốc độ: Tốc độ truyền và tạo dữ liệu.
- Giá trị: Ý nghĩa của dữ liệu về mặt thông tin mà các nhà nghiên cứu có thể suy ra từ nó.
- Tính xác thực: Tính chắc chắn và đúng đắn trong dữ liệu mà chúng tôi đang nghiên cứu.
Kết luận về Data trong Học máy
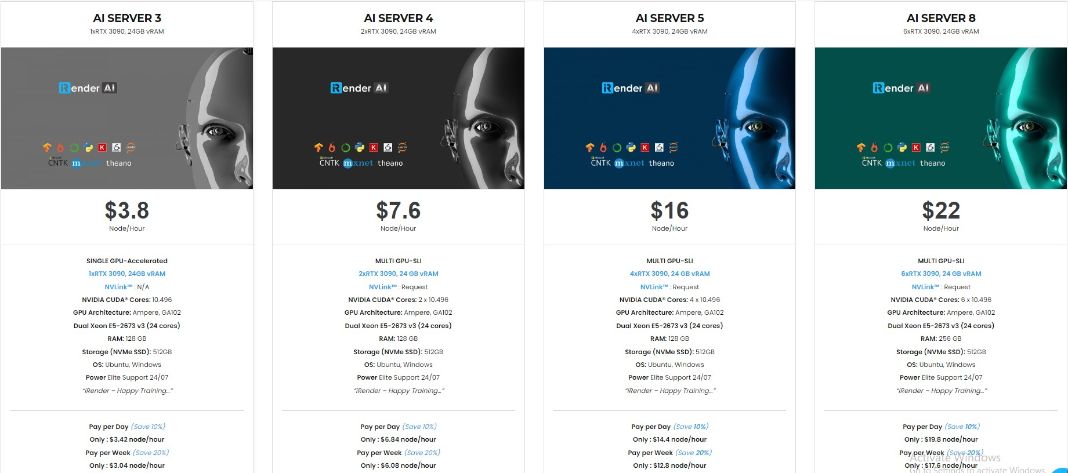
Tại iRender, chúng tôi cung cấp giải pháp nhanh chóng, mạnh mẽ và hiệu quả cho người dùng Deep Learning với cấu hình gói từ 1 đến 6 GPU RTX 3090 trên cả hai hệ điều hành Windows và Ubuntu. Ngoài ra, chúng tôi còn có GPU cấu hình gói từ 1 RTX 3090 và 8 x RTX 3090. Với dịch vụ hỗ trợ chuyên nghiệp 24/7, công cụ lưu trữ và truyền dữ liệu mạnh mẽ, miễn phí và tiện lợi – GPUhub Sync, cùng với chi phí phải chăng giúp công việc quả bạn hiệu quả hơn.
Đăng ký tài khoản ngay hôm nay để trải nghiệm dịch vụ của chúng tôi. Hoặc liên hệ với chúng tôi, tôi thông qua Zalo: (+84) 912 785 500 để được tư vấn và hỗ trợ.
Nguồn tham khảo: geeksforgeeks.org