Khoa học dữ liệu, Học máy và Trí tuệ nhân tạo
Trong khi các thuật ngữ Khoa học dữ liệu (Data Science), Trí tuệ nhân tạo (Artificial Intelligence -AI) và Học máy (Machine Learning) nằm trong cùng một miền và được kết nối với nhau, chúng có các ứng dụng và ý nghĩa cụ thể của mình. Đôi khi, có thể có sự trùng lặp trong các miền này, nhưng về cơ bản, mỗi thuật ngữ trong ba thuật ngữ này có cách sử dụng riêng của chúng. Dưới đây là một bản tóm tắt về Khoa học dữ liệu với Học máy và Trí tuệ nhân tạo.

1. Khoa học dữ liệu là gì?
Chắc hẳn cũng có lúc bạn tự hỏi, Khoa Học Dữ Liệu là gì?, Khoa Học Dữ Liệu (Data Science) là một lĩnh vực nghiên cứu rộng lớn liên quan đến các hệ thống và quy trình dữ liệu, nhằm mục đích duy trì các tập dữ liệu và rút ra ý nghĩa của chúng. Các nhà khoa học dữ liệu sử dụng kết hợp các công cụ, ứng dụng, nguyên tắc và các thuật toán để hiểu được các cụm dữ liệu ngẫu nhiên. Vì hầu hết tất cả các tổ chức ngày nay đang tạo ra lượng dữ liệu theo cấp số nhân trên toàn thế giới, nên việc theo dõi và lưu trữ dữ liệu này trở nên vô cùng khó khăn. Khoa học dữ liệu tập trung vào mô hình hóa dữ liệu và lưu trữ dữ liệu để theo dõi tập dữ liệu ngày càng phát triển. Thông tin được trích xuất thông qua các ứng dụng khoa học dữ liệu được sử dụng để hướng dẫn các quy trình kinh doanh và đạt được các mục tiêu của tổ chức.

Phạm vi của khoa học dữ liệu
Một trong những lĩnh vực mà Khoa học dữ liệu ảnh hưởng trực tiếp là Kinh doanh thông minh (Business Intelligence). Phải nói rằng, có những chức năng dành riêng cho từng vai trò này. Các nhà khoa học dữ liệu chủ yếu xử lý các khối dữ liệu khổng lồ để phân tích các mô hình, xu hướng và nhiều hơn nữa. Các ứng dụng phân tích này tạo ra các báo cáo cuối cùng hữu ích trong việc rút ra các kết luận. Một chuyên gia về Business Intelligence chọn nơi một nhà khoa học dữ liệu rời đi – sử dụng các báo cáo khoa học dữ liệu để hiểu xu hướng dữ liệu trong bất kỳ lĩnh vực kinh doanh cụ thể nào và đưa ra các dự báo kinh doanh và quá trình hành động dựa trên những suy luận này. Thật thú vị, cũng có một lĩnh vực liên quan sử dụng cả Khoa học dữ liệu, phân tích dữ liệu và ứng dụng Kinh doanh thông minh, đó là Chuyên viên phân tích nghiệp vụ. Một hồ sơ phân tích kinh doanh kết hợp một chút của cả hai để giúp các công ty đưa ra quyết định dựa trên các dữ liệu.
Các nhà khoa học dữ liệu phân tích dữ liệu lịch sử theo các yêu cầu khác nhau, bằng cách áp dụng các định dạng khác nhau, cụ thể:
- Phân tích nguyên nhân dự đoán: Các nhà khoa học dữ liệu sử dụng mô hình này để đưa ra dự báo kinh doanh. Mô hình dự đoán cho thấy kết quả của các hành động kinh doanh khác nhau trong các điều khoản có thể đo lường được. Đây có thể là một mô hình hiệu quả cho các doanh nghiệp đang cố gắng hiểu tương lai của bất kỳ động thái kinh doanh mới nào.
- Phân tích theo quy định: Loại phân tích này giúp doanh nghiệp đặt mục tiêu bằng cách quy định các hành động có khả năng thành công nhất. Phân tích theo quy định sử dụng các suy luận từ mô hình dự đoán và giúp các doanh nghiệp bằng cách đề xuất các cách tốt nhất để đạt được các mục tiêu đó.
Khoa học dữ liệu sử dụng một loạt các công nghệ định hướng dữ liệu bao gồm SQL, Python, R, và Hadoop, v.v. . Tuy nhiên, nó cũng sử dụng rộng rãi các phân tích thống kê, trực quan hóa dữ liệu, kiến trúc phân tán và nhiều thứ khác để trích xuất ý nghĩa của các bộ dữ liệu.
Các nhà khoa học dữ liệu là các chuyên gia lành nghề có chuyên môn cho phép họ nhanh chóng chuyển đổi vai trò tại bất kỳ thời điểm nào trong vòng đời của các dự án khoa học dữ liệu. Họ có thể làm việc với Trí tuệ nhân tạo và Học máy dễ dàng như nhau. Trên thực tế, các nhà khoa học dữ liệu cần các kỹ năng học máy cho các yêu cầu cụ thể như:
- Học máy cho Báo cáo dự đoán: Các nhà khoa học dữ liệu sử dụng thuật toán Học máy để nghiên cứu dữ liệu giao dịch để đưa ra các dự đoán có giá trị. Còn được gọi là Học có giám sát, mô hình này có thể được thực hiện để đề xuất các khóa học hành động hiệu quả nhất cho bất kỳ công ty nào.
- Học máy cho khám phá mẫu: Phát hiện mẫu rất quan trọng đối với các doanh nghiệp để đặt tham số trong các báo cáo dữ liệu khác nhau và cách thực hiện là thông qua học máy. Điều này về cơ bản là học tập không giám sát, nơi không có các tham số được quyết định trước. Thuật toán phổ biến nhất được sử dụng để khám phá mẫu là Clustering.
2. Trí tuệ nhân tạo là gì?
AI – Trí tuệ nhân tạo, một thuật ngữ công nghệ khá rắc rối được sử dụng thường xuyên và phổ biến – được liên kết bởi các robot có vẻ ngoài do con người tưởng tượng ra trong tương lai và một thế giới được thống trị bởi máy móc. Tuy nhiên, trên thực tế, Trí tuệ nhân tạo còn lâu mới đạt được điều đó.
Nói một cách đơn giản, trí tuệ nhân tạo cho phép máy móc thực hiện các suy luận bằng cách tái tạo trí thông minh của con người. Vì mục tiêu chính của các quy trình AI là dạy cho máy móc các kinh nghiệm, do vậy việc cung cấp thông tin đúng và khả năng tự điều chỉnh là rất quan trọng. Các chuyên gia AI dựa vào việc học sâu và xử lý ngôn ngữ tự nhiên để giúp máy móc xác định các mô hình và suy luận.

Phạm vi của trí tuệ nhân tạo
- Tự động hóa dễ dàng với AI: AI cho phép bạn tự động hóa các tác vụ lặp lại, khối lượng lớn bằng cách thiết lập các hệ thống đáng tin cậy chạy các ứng dụng một cách thường xuyên.
- Sản phẩm thông minh: AI có thể biến các sản phẩm thông thường thành các hàng hóa thông minh. Các ứng dụng AI khi được kết hợp với các nền tảng đàm thoại, bot và các máy thông minh khác có thể dẫn đến các công nghệ được cải tiến.
- Học tập tiến bộ: Các thuật toán AI có thể đào tạo máy móc để thực hiện bất kỳ chức năng mong muốn nào. Các thuật toán làm việc như dự đoán và phân loại.
- Phân tích dữ liệu: Vì các máy học từ dữ liệu chúng ta cung cấp cho chúng, việc phân tích và xác định đúng bộ dữ liệu trở nên rất quan trọng. Mạng neural khiến cho việc đào tạo máy móc dễ dàng hơn.
3. Học máy (Machine Learning) là gì?
Machine Learning là một phần của Trí tuệ nhân tạo theo đó các hệ thống có thể tự động học hỏi và cải thiện từ kinh nghiệm. Nhánh đặc biệt này của AI nhằm mục đích trang bị máy móc với các kỹ thuật học tập độc lập để chúng không phải lập trình để làm điều đó, đây là điểm khác biệt giữa AI và Machine Learning.
Machine learning bao gồm quan sát và nghiên cứu dữ liệu hoặc kinh nghiệm để xác định các mẫu và thiết lập một hệ thống lý luận dựa trên các phát hiện. Các thành phần khác nhau của Machine learning bao gồm:
- Machine learning được giám sát: Mô hình này sử dụng dữ liệu lịch sử để hiểu hành vi và hình thành dự báo trong tương lai. Loại thuật toán học tập này phân tích bất kỳ tập dữ liệu đào tạo nhất định nào để rút ra các kết luận có thể được áp dụng cho các giá trị đầu ra. Các tham số học tập được giám sát là rất quan trọng trong việc ánh xạ cặp đầu vào-đầu ra.
- Machine learning không giám sát: Loại thuật toán Machine learning này không sử dụng bất kỳ tham số được phân loại hoặc dán nhãn nào. Nó tập trung vào việc khám phá các cấu trúc ẩn từ dữ liệu chưa được gắn nhãn để giúp các hệ thống suy luận đúng chức năng. Các thuật toán với Machine learning không giám sát có thể sử dụng cả mô hình học tập tổng quát và phương pháp tiếp cận dựa trên truy xuất.
- Machine learning bán giám sát: Mô hình này kết hợp các yếu tố của Machine learning có giám sát và Machine learning không giám sát nhưng không phải là một trong số chúng. Nó hoạt động bằng cách sử dụng cả dữ liệu được dán nhãn và không nhãn để cải thiện độ chính xác trong quá trình học. Machine learning bán giám sát có thể là một giải pháp hiệu quả về chi phí khi việc dán nhãn dữ liệu trở nên đắt đỏ.
- Machine learning gia cố: Kiểu học này không sử dụng bất kỳ phím trả lời nào để hướng dẫn thực hiện bất kỳ chức năng nào. Việc thiếu kết quả dữ liệu đào tạo trong quá trình học tập kinh nghiệm. Quá trình thử nghiệm và sai sót cuối cùng dẫn đến hiệu quả dài hạn.
Machine learning (ML) mang lại kết quả chính xác thu được thông qua việc phân tích các tập dữ liệu lớn. Áp dụng các công nghệ nhận thức AI vào các hệ thống ML có thể giúp xử lý dữ liệu và thông tin hiệu quả. Nhưng sự khác biệt chính giữa Khoa học dữ liệu so với Machine Learning và AI với Machine learning là gì?
4. Sự khác biệt giữa AI và Machine Learning
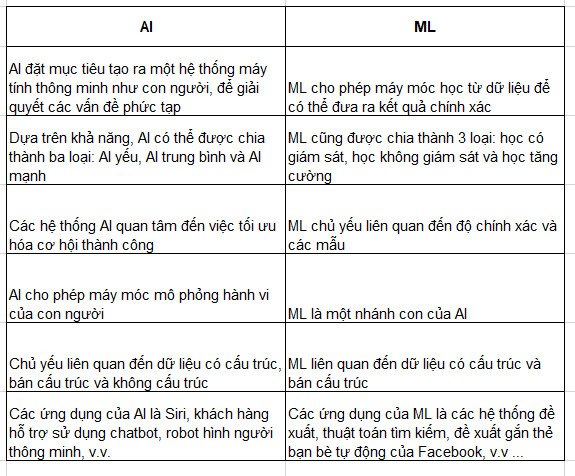
5. Mối quan hệ giữa Khoa học dữ liệu, Trí tuệ nhân tạo và Học máy
Trí tuệ nhân tạo và khoa học dữ liệu là một lĩnh vực các ứng dụng, hệ thống rộng lớn và nhiều hơn nữa nhằm mục đích tái tạo trí thông minh của con người thông qua máy móc. Trí tuệ nhân tạo đại diện cho một phản hồi có kế hoạch hành động về nhận thức.
Nhận thức> Lập kế hoạch> Hành động> Phản hồi về nhận thức
Khoa học dữ liệu sử dụng các phần khác nhau của mẫu hoặc vòng lặp này để giải quyết các vấn đề cụ thể. Chẳng hạn, trong bước đầu tiên, tức là nhận thức, các nhà khoa học dữ liệu cố gắng xác định các mẫu với sự trợ giúp của dữ liệu. Tương tự, trong bước tiếp theo, tức là lập kế hoạch, có hai khía cạnh:
- Tìm tất cả các giải pháp có thể
- Tìm giải pháp tốt nhất trong số tất cả các giải pháp
Khoa học dữ liệu tạo ra một hệ thống liên quan đến tất cả những điểm đã nói ở trên và giúp doanh nghiệp phát triển.
Mặc dù nó có thể giải thích việc Học máy bằng cách lấy nó làm chủ đề độc lập, nhưng nó có thể được hiểu rõ nhất trong bối cảnh môi trường của nó, tức là, hệ thống mà nó sử dụng trong đó.
Nói một cách đơn giản, Học máy là liên kết kết nối Khoa học dữ liệu và AI. Đó là bởi vì nó là quá trình học hỏi từ dữ liệu theo thời gian. Vì vậy, AI là công cụ giúp khoa học dữ liệu có được kết quả và giải pháp cho các vấn đề cụ thể. Tuy nhiên, Học máy là thứ giúp đạt được mục tiêu đó. Một ví dụ thực tế về điều này là Công cụ Tìm kiếm Google.
- Công cụ tìm kiếm Google là một sản phẩm của Khoa học dữ liệu
- Nó sử dụng phân tích dự đoán, một hệ thống được sử dụng bởi trí tuệ nhân tạo, để cung cấp kết quả thông minh cho người dùng.
- Chẳng hạn, nếu một người gõ áo khoác tốt nhất của New York trên công cụ tìm kiếm Google, thì AI sẽ thu thập thông tin này thông qua Học máy
- Bây giờ, ngay khi người đó viết từ này vào công cụ tìm kiếm “nơi tốt nhất để mua”, thì AI bắt đầu với phân tích dự đoán sẽ hoàn thành câu như “một nơi tốt nhất để mua áo khoác ở NY”. Đây là hậu tố có thể xảy ra nhất truy vấn mà người dùng đã nghĩ đến.
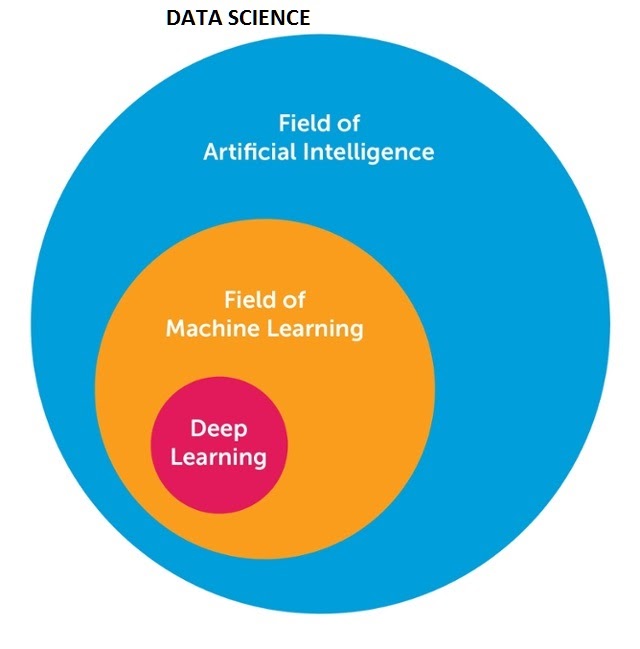
Nói chính xác, Khoa học dữ liệu bao gồm AI, AI bao gồm Học máy. Tuy nhiên, bản thân Học máy bao gồm một công nghệ phụ khác – Deep Learning.
Deep Learning là một hình thức học máy nhưng khác với việc sử dụng Mạng Neural, nơi chúng tôi kích thích chức năng của não đến một mức độ nhất định và sử dụng hệ thống phân cấp 3D trong dữ liệu để xác định các mẫu hữu ích hơn nhiều.
6. Sự khác biệt giữa Khoa học dữ liệu, Trí tuệ nhân tạo và Học máy
Mặc dù thuật ngữ Khoa học dữ liệu, Trí tuệ nhân tạo và Học máy có thể liên quan và liên kết với nhau, mỗi thuật ngữ này lại là duy nhất theo cách riêng của chúng và được sử dụng cho các mục đích khác nhau. Khoa học dữ liệu là một thuật ngữ rộng và bao gồm cả Machine Learning. Ở đây, sự khác biệt chính giữa các điều khoản.
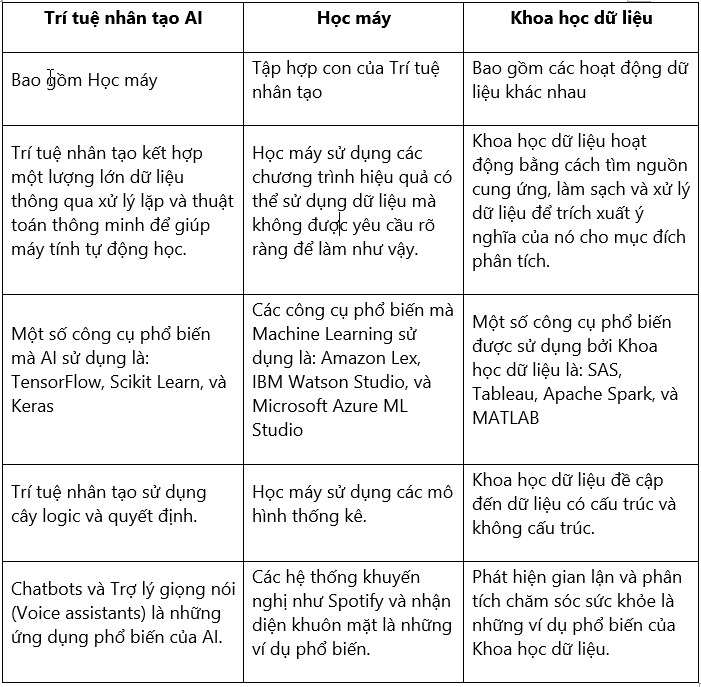
Mặc dù các lĩnh vực Khoa học dữ liệu so với Học máy và Trí tuệ nhân tạo có sự chồng chéo lẫn nhau, các chức năng cụ thể của chúng khác nhau và có các lĩnh vực ứng dụng tương ứng riêng. Thị trường khoa học dữ liệu đã mở ra một số ngành dịch vụ và sản phẩm, tạo cơ hội cho các chuyên gia trong lĩnh vực này.
Hiện nay, iRender chính thức ra mắt dịch vụ Gpu Cloud For AI/Deep Learning, mang đến cho người dùng trải nghiệm mới trong quá trình Build & Train & Tune dự án AI/DeepLearning thật dễ dàng, nhanh chóng, thuận tiện và hiệu quả.
Đăng kí account tại đây để trải nghiệm dịch vụ của iRender.
Nguồn: www.mygreatlearning.com