CUDA Refresher: Cùng nhìn lại nguồn gốc của việc tính toán trên GPU
Đây là bài đăng đầu tiên trong series CUDA Refresher, với mục tiêu làm mới các khái niệm chính trong CUDA, các công cụ và việc tối ưu hoá, đặc biệt dành cho các lập trình viên mới và cấp trung.
Như bạn đã thấy, nhu cầu về điện toán đang ngày càng tăng nhờ có ngày càng nhiều khám phá về khoa học hay về Business Analytics. Những ứng dụng thực tế như là Dự báo thời tiết, mô phỏng tính toán động lực học chất lưu (CFD (Computational Fluid Dynamics): Tính toán động lực học chất lưu, các vấn đề về khí động học trong kỹ thuật, mô phỏng tác động của dòng chảy nhiệt trong các quá trình). Gần đây nhất, Machine Learning và Deep Learning bùng nổ mạnh mẽ đã cho chúng ta thấy điện toán (computing) quan trọng như thế nào, khi ML và DL càng phát triển, càng cần một công suất tính toán lớn hơn mức nó hiện có và với các thuật toán phức tạp hơn thì ta cần nhiều hiệu suất tính toán hơn để chạy.
Từ trước tới nay, ngành công nghiệp điện toán đã dùng những cách thức khác nhau để đạt được mức hiệu năng cần thiết, ví dụ như tăng mật độ transistor, xử lý song song cấp tập lệnh ILP (instruction-level parallelism), thang đo Dennard,…
- Tốc độ tăng số transistors trong một chip theo thời gian, tuân theo một trong những quy luật nổi tiếng nhất trong máy tính là luật Moore: số lượng transistor trong một chip sẽ tăng lên gấp đôi cứ sau 18 tháng. Đây là tốc độ tăng của hàm mũ, từ năm 1970 các chips chỉ có khoảng 10 nghìn transistors mà đến những năm 2010 thì con số này đã lên tới 10 tỉ (Theo Khải Trần).
- Các kỹ thuật như ILP cũng giúp tăng hiệu suất nhưng kết quả mang lại bắt đầu giảm dần bắt đầu từ khoảng năm 2001.
- Thang đo Dennard cũng mang lại các lợi ích cùng với luật Moore cho đến năm 2005 khi voltage scaling kết thúc
Khoảng năm 2005, việc tăng/thu nhỏ quy mô tính toán bắt đầu đi xuống và ngành công nghiệp này cần các giải pháp thay thế để đáp ứng nhu cầu điện toán. Rõ ràng là hiệu suất trong tương lai phụ thuộc nhiều vào tính toán song song.
Những nhân tố quan trọng khác chính là sức mạnh và khả năng giao tiếp. Các nghiên cứu cho thấy sức mạnh chủ yếu được dành cho giao tiếp, vì vậy giao tiếp nhiều hơn có nghĩa là nhiều sức mạnh hơn và hạn chế số lượng tính toán có thể được đưa vào một máy. Điều này ngụ ý rằng tính toán trong tương lai nên tiết kiệm năng lượng và những yếu tố trên được ưu tiên hơn.
Thời đại của GPGPU
Trong những năm 90 và những năm 2000, phần cứng đồ họa được thiết kế để phục vụ các nhu cầu cụ thể, đặc biệt cho ngành công nghiệp đồ hoạ. Nhưng khối lượng công việc đồ họa đòi hỏi sức mạnh tính toán ngày càng tăng. Kết quả là, hiệu suất tăng khoảng ~ 2,4 lần / năm so với những gì mà transistor có thể cung cấp (~ 1,8 lần / năm). Hình ảnh dưới đây cho thấy quỹ đạo hiệu suất đồ họa nổi tiếng của Giáo sư John Poulton từ Đại học Bắc Carolina (UNC).
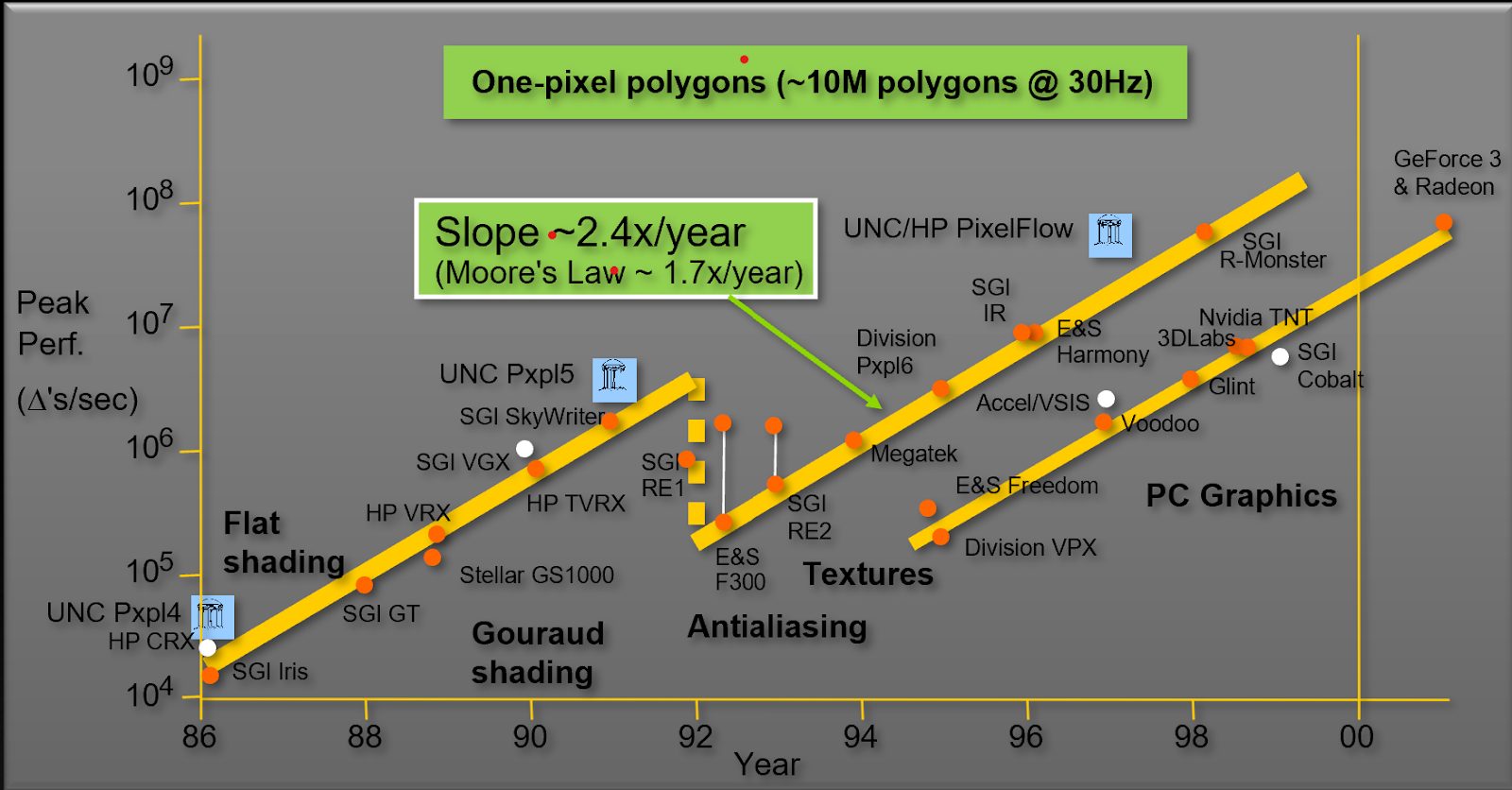
Sử dụng số liệu metric of triangles mỗi giây ta thấy phần cứng đồ họa đã tăng hiệu suất hơn 2,4 lần mỗi năm, nhanh hơn so với luật Moore dự đoán. Điều này là do lượng lớn tính toán song song có sẵn trong các tính toán đồ hoạ máy tính mà phần cứng có thể tận dụng. Năm 2001, đồ họa máy tính đã đặt dấu chấm hết cho các hệ thống lớn được thiết kế riêng cho đồ hoạ.
Còn đối với cộng đồng lập trình viên, đây là động lực để khai thác mã lực tính toán đáng kinh ngạc từ phần cứng đồ họa và tăng tốc khối lượng công việc khoa học như hình ảnh y tế, điện từ và nhiều hơn nữa.
GPU của NVIDIA ban đầu được thiết kế cho games và các công việc liên quan tới đồ hoạ mà bản chất cần tính toán song song. Do nhu cầu cao về FLOPS và băng thông bộ nhớ trong ngành công nghiệp games và đồ họa, GPU đã phát triển thành bộ xử lý nhiều lõi song song, đa luồng, với mã lực tính toán khổng lồ và băng thông bộ nhớ cao. Điều này đã bắt đầu cho kỷ nguyên của GPGPU (General-purpose computing on GPU) mà ban đầu được thiết kế để chỉ tăng tốc độ xử lý cụ thể như chơi game và đồ họa.
Mô hình điện toán lai (Hybrid Computing Model)
GPU được thiết kế để tính toán song song cao và còn được gọi là bộ xử lý thông lượng. Có nhiều dự án về khoa học và AI cần tính toán song song rất lớn trong thuật toán của chúng và có thể chạy rất chậm trên CPU.
GPU tăng tốc các ứng dụng chạy trên CPU bằng cách giảm tải một số phần mã tốn nhiều thời gian và tính toán của mã. Phần còn lại của ứng dụng vẫn chạy trên CPU. Ứng dụng chạy nhanh hơn vì nó sử dụng sức mạnh xử lý song song của GPU để tăng hiệu suất.
Với sự gia tăng của điện toán lai, cả hai bộ xử lý cùng tồn tại nhưng chúng vẫn khác nhau về cơ bản. Hình 2 cho thấy sự khác biệt cơ bản giữa CPU và GPU.
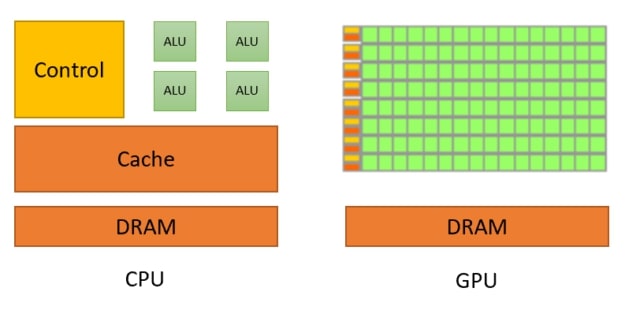
GPU dành hầu hết transistors của chúng để xử lý dữ liệu trong khi CPU dành khu vực chết cho bộ nhớ đệm cache lớn, bộ điều khiển, v.v. Bộ xử lý CPU hoạt động theo nguyên tắc giảm thiểu độ trễ trong mỗi luồng trong khi GPU ẩn độ trễ của lệnh và bộ nhớ với tính toán. Hình 3 cho thấy sự khác biệt trong các luồng tính toán.
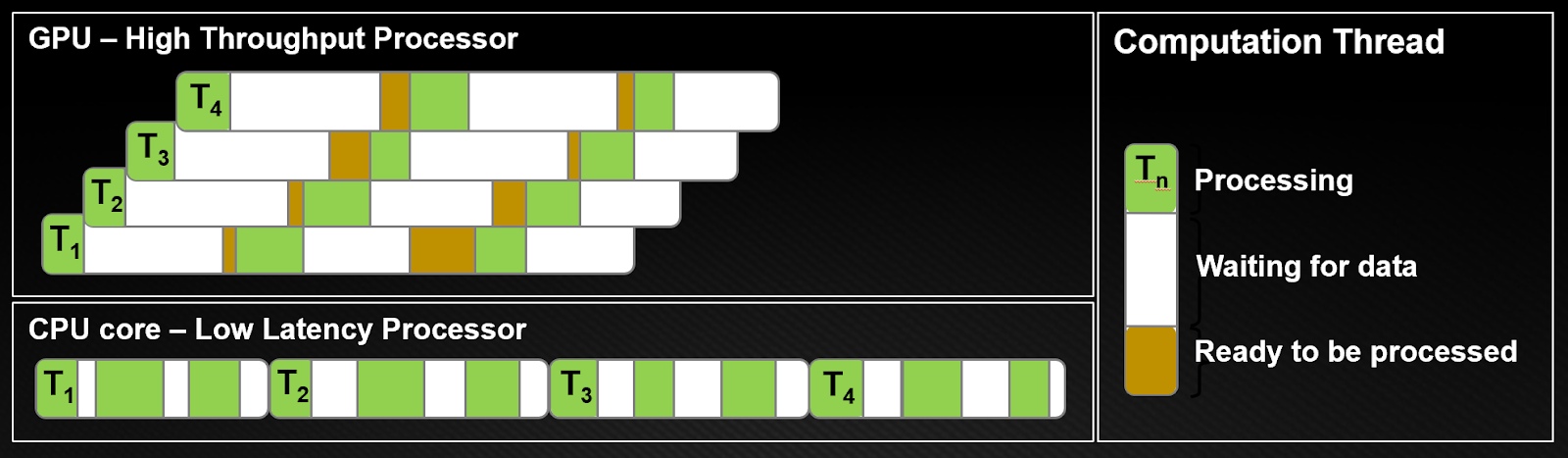
Từ hình 3, ta thấy hiển nhiên các kiến trúc CPU phải giảm thiểu độ trễ trong mỗi luồng. Trên CPU, mọi luồng đều giảm thiểu thời gian truy cập dữ liệu (thanh màu trắng). Trong một khoảng thời gian đơn (a single time slice), luồng hoàn thành công việc càng nhiều càng tốt (thanh màu xanh lá cây). Để đạt được điều này, CPU yêu cầu độ trễ thấp, đòi hỏi bộ nhớ cache lớn và logic điều khiển phức tạp. Bộ nhớ cache hoạt động tốt nhất chỉ với một vài luồng trên mỗi lõi, vì chuyển đổi ngữ cảnh giữa các luồng rất tốn kém.
Kiến trúc GPU đã ẩn hướng dẫn và độ trễ bộ nhớ với tính toán. Trong GPU, các luồng rất nhẹ, do đó, GPU có thể chuyển từ các luồng bị đình trệ sang các luồng khác mà không mất chi phí thường xuyên như mọi chu kỳ xung nhịp.
Như Hình 3, khi luồng T1 bị đình trệ dữ liệu, một luồng khác T2 bắt đầu xử lý, v.v. với T3 và T4. Trong khi đó, T1 cuối cùng cũng có được dữ liệu để xử lý. Theo cách này, độ trễ được che giấu bằng cách chuyển sang công việc khác, có sẵn. Điều này có nghĩa là GPU cần nhiều luồng đồng thời chồng chéo để che giấu độ trễ. Kết quả là, bạn có thể chạy hàng ngàn luồng trên GPU.
Để biết thêm thông tin, xem Hướng dẫn lập trình CUDA.
Machine Learning đang dần phụ thuộc vào GPU, vào tính toán song song. Nhận thấy xu hướng trong tương lai về tầm quan trọng của GPU đối với AI, iRender chúng tôi đang phát triển và dần hoàn thiện dịch vụ GPUHub – AI, dịch vụ cho thuê máy tính theo giờ với cấu hình GPU và CPU mạnh mẽ. Chúng tôi cung cấp 1-6 cards x GTX 1080 Ti và 1-6 cards x RTX 2080 Ti, giúp tốc độ Training set, Cross validation set và Test set diễn ra nhanh hơn cũng như xử lý trơn tru hơn. Nếu bạn cần trợ giúp, đội ngũ hỗ trợ kỹ thuật và tư vấn trực tiếp 24/7 của chúng tôi luôn sẵn sàng – đơn giản chỉ là một cú click chuột.
Hãy đăng ký tại đây để sử dụng dịch vụ của chúng tôi.
Nguồn: nvidia.com