Chọn GPU tốt nhất cho Deep Learning năm 2020

Các mô hình deep learning hiện đại nhất (SOTA- State of the art) có bộ nhớ footprints lớn. Nhiều GPU không có đủ VRAM để đào tạo chúng. Trong bài đăng này, chúng tôi xác định GPU nào có thể đào tạo các mạng tiên tiến nhất mà không gây ra lỗi bộ nhớ. Chúng tôi cũng điểm chuẩn hiệu suất đào tạo của mỗi GPU.
TLDR:
Các GPU sau có thể đào tạo tất cả các SOTA language và image models kể từ tháng 2 năm 2020:
- RTX 8000: 48 GB VRAM, ~ 5.500 USD.
- RTX 6000: 24 GB VRAM, ~ 4.000 USD.
- Titan RTX: 24 GB VRAM, ~ 2.500 USD.
Các GPU sau có thể đào tạo hầu hết (nhưng không phải tất cả) các SOTA models:
- RTX 2080 Ti: VRAM 11 GB, ~ 1.150 USD. *
- GTX 1080 Ti: VRAM 11 GB, tân trang ~ 800 USD. *
- RTX 2080: VRAM 8 GB, ~ 720 USD. *
- RTX 2070: VRAM 8 GB, ~ 500 đô la. *
GPU sau không phù hợp để đào tạo các mô hình SOTA:
- RTX 2060: VRAM 6 GB, ~ $ 359.
* Việc đào tạo trên các GPU này đòi hỏi batch size nhỏ, do đó, mong đợi độ chính xác của model thấp hơn vì tính gần đúng của cảnh quan năng lượng của model sẽ bị tổn hại.
* Batch size là số lượng mẫu dữ liệu trong một batch
Image models (Mô hình hình ảnh)
Batch size tối đa trước khi hết bộ nhớ
| Model / GPU | 2060 | 2070 | 2080 | 1080 Ti | 2080 Ti | Titan RTX | RTX 6000 | RTX 8000 |
| NasNet Large | 4 | 8 | 8 | 8 | 8 | 32 | 32 | 64 |
| DeepLabv3 | 2 | 2 | 2 | 4 | 4 | 8 | 8 | 16 |
| Yolo v3 | 2 | 4 | 4 | 4 | 4 | 8 | 8 | 16 |
| Pix2Pix HD | * | * | * | * | * | 1 | 1 | 2 |
| StyleGAN | 1 | 1 | 1 | 4 | 4 | 8 | 8 | 16 |
| MaskRCNN | 1 | 2 | 2 | 2 | 2 | 8 | 8 | 16 |
* GPU không có đủ bộ nhớ để chạy mô hình.
Hiệu suất, được đo bằng hình ảnh được xử lý mỗi giây
| Model / GPU | 2060 | 2070 | 2080 | 1080 Ti | 2080 Ti | Titan RTX | RTX 6000 | RTX 8000 |
| NasNet Large | 7.3 | 9.2 | 10.9 | 10.1 | 12.9 | 16.3 | 13.9 | 15.6 |
| DeepLabv3 | 4.4 | 4.82 | 5.8 | 5.43 | 7.6 | 9.01 | 8.02 | 9.12 |
| Yolo v3 | 7.8 | 9.15 | 11.08 | 11.03 | 14.12 | 14.22 | 12.8 | 14.22 |
| Pix2Pix HD | * | * | * | * | * | 0.73 | 0.71 | 0.71 |
| StyleGAN | 1.92 | 2.25 | 2.6 | 2.97 | 4.22 | 4.94 | 4.25 | 4.96 |
| MaskRCNN | 2.85 | 3.33 | 4.36 | 4.42 | 5.22 | 6.3 | 5.54 | 5.84 |
* GPU không có đủ bộ nhớ để chạy mô hình.
Language models (Mô hình ngôn ngữ)
Batch size tối đa trước khi hết bộ nhớ
| Model / GPU | Units | 2060 | 2070 | 2080 | 1080 Ti | 2080 Ti | Titan RTX | RTX 6000 | RTX 8000 |
| Transformer Big | Tokens | * | 2000 | 2000 | 4000 | 4000 | 8000 | 8000 | 16000 |
| Conv. Seq2Seq | Tokens | * | 2000 | 2000 | 3584 | 3584 | 8000 | 8000 | 16000 |
| unsupMT | Tokens | * | 500 | 500 | 1000 | 1000 | 4000 | 4000 | 8000 |
| BERT Base | Sequences | 8 | 16 | 16 | 32 | 32 | 64 | 64 | 128 |
| BERT Finetune | Sequences | 1 | 6 | 6 | 6 | 6 | 24 | 24 | 48 |
| MT-DNN | Sequences | * | 1 | 1 | 2 | 2 | 4 | 4 | 8 |
* GPU không có đủ bộ nhớ để chạy mô hình.
Hiệu suất
| Model / GPU | Units | 2060 | 2070 | 2080 | 1080 Ti | 2080 Ti | Titan RTX | RTX 6000 | RTX 8000 |
| Transformer Big | Words/sec | * | 4597 | 6317 | 6207 | 7780 | 8498 | 7407 | 7507 |
| Conv. Seq2Seq | Words/sec | * | 7721 | 9950 | 5870 | 15671 | 21180 | 20500 | 22450 |
| unsupMT | Words/sec | * | 1010 | 1212 | 1824 | 2025 | 3850 | 3725 | 3735 |
| BERT Base | Ex./sec | 34 | 47 | 58 | 60 | 83 | 102 | 98 | 94 |
| BERT Finetue | Ex./sec | 7 | 15 | 18 | 17 | 22 | 30 | 29 | 27 |
| MT-DNN | Ex./sec | * | 3 | 4 | 8 | 9 | 18 | 18 | 28 |
* GPU không có đủ bộ nhớ để chạy mô hình.
Kết quả được chuẩn hóa bởi Quadro RTX 8000
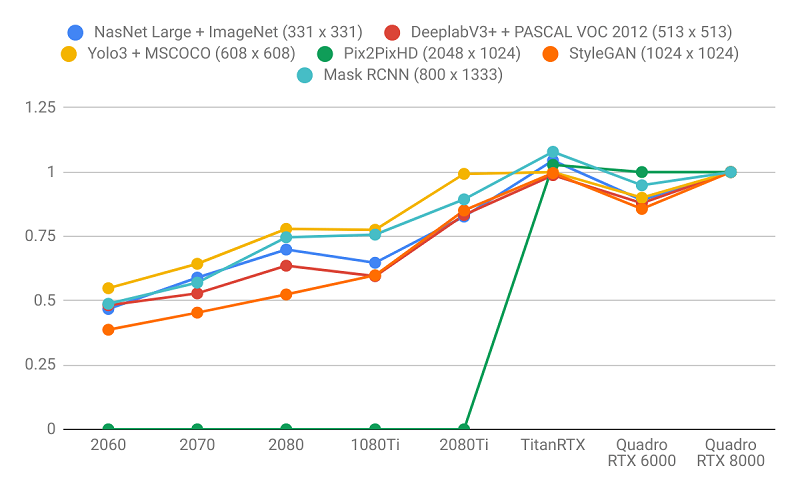
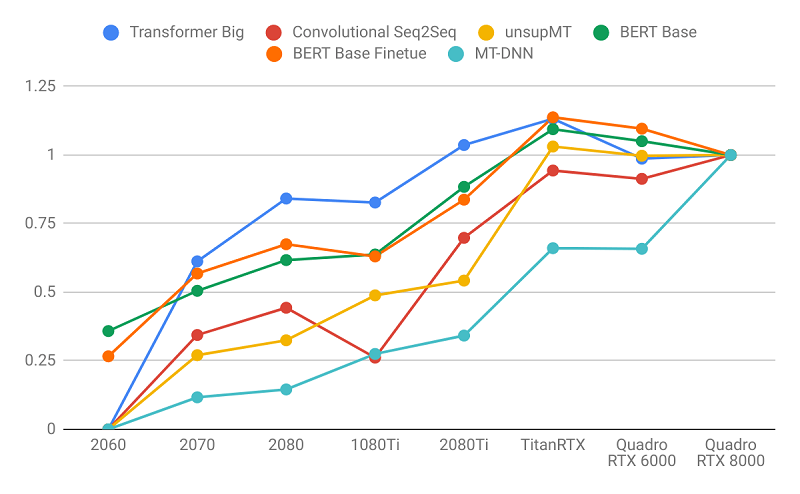
Hình ảnh mô tả thông lượng đào tạo được chuẩn hóa theo Quadro RTX 8000.
Kết luận
- Các language models được hưởng lợi nhiều hơn từ bộ nhớ GPU lớn hơn các image models. Lưu ý cách sơ đồ bên phải dốc hơn bên trái. Điều này chỉ ra rằng các language models bị ràng buộc nhiều bộ nhớ hơn và các image models bị giới hạn tính toán nhiều hơn.
- GPU có VRAM cao hơn có hiệu suất tốt hơn vì sử dụng kích thước lô lớn hơn giúp bão hòa các lõi CUDA.
- GPU có VRAM cao hơn cho phép batch size lớn hơn tương ứng. Tính toán Back-of-the-envelope mang lại kết quả hợp lý: GPU có VRAM 24 GB có thể phù hợp với batch lớn hơn ~ 3 lần so với GPU có 8 GB VRAM.
- Các language models chiếm bộ nhớ không cân xứng cho các chuỗi dài vì bậc hai đối với độ dài chuỗi cần được chú ý.
* Back-of-the-envelope là tính toán sơ bộ, không chỉ là phỏng đoán mà còn sử dụng các giả định đơn giản hoá.
Khuyến nghị về GPU
- RTX 2060 (6 GB):nếu bạn muốn khám phá deep learning trong thời gian rảnh rỗi.
- RTX 2070 hoặc 2080 (8 GB):nếu bạn nghiêm túc về deep learning , nhưng ngân sách GPU của bạn là 600-800 $. 8GB VRAM có thể phù hợp với phần lớn các mô hình.
- RTX 2080 Ti (11 GB):nếu bạn nghiêm túc về deep learning và ngân sách GPU của bạn là ~ 1.200 $. RTX 2080 Ti nhanh hơn ~ 40% so với RTX 2080.
- Titan RTX và Quadro RTX 6000 (24 GB):nếu bạn đang làm việc trên các mô hình SOTA mở rộng, nhưng không có ngân sách cho việc chứng minh trong tương lai có sẵn với RTX 8000.
- Quadro RTX 8000 (48 GB):bạn đang đầu tư vào tương lai và thậm chí có thể đủ may mắn để nghiên cứu SOTA deep learning vào năm 2020.
Hiện nay, tại iRender đang cung cấp hệ thống máy tính với hiệu suất của cấu hình máy tính có GPU mạnh mẽ . Với chi phí rất rẻ, bạn đã được sở hữu ngay con máy với card RTX 2080Ti đào tạo các mô hình cho Deep Learning.
Hãy đăng ký tài khoản mới tại đây và liên hệ với chúng tôi để được trải nghiệm GPU phục vụ cho công cuộc Deep Learning trong năm 2020.
Chú thích
Image Models (Mô hình hình ảnh)
| Mô hình | Bài tập | Bộ dữ liệu | Kích cỡ hình | Repo |
| NasNet Lớn | Phân loại hình ảnh | ImageNet | 331×31 | Github |
| DeepLabv3 | Phân đoạn hình ảnh | VOC PASCAL | 513×513 | GitHub |
| Yolo v3 | Phát hiện đối tượng | MSCOCO | 608×608 | GitHub |
| Pix2Pix HD | Cách điệu hình ảnh | CityScape | 2048×1024 | GitHub |
| StyleGAN | Tạo hình ảnh | FFHQ | 1024×1024 | GitHub |
| MaskRCNN | Phân đoạn sơ thẩm | MSCOCO | 800×1333 | GitHub |
Language Models (Mô hình ngôn ngữ)
| Mô hình | Bài tập | Bộ dữ liệu | Repo |
| Máy biến áp lớn | Dịch máy giám sát | WMT16_en_de | GitHub |
| Conv. Seq2Seq | Dịch máy giám sát | WMT14_en_de | GitHub |
| không phục vụ | Dịch máy không giám sát | NewsCrawl | GitHub |
| Cơ sở BERT | Mô hình hóa ngôn ngữ | enwik8 | GitHub |
| BERT Finetune | Câu hỏi và trả lời | SQUAD 1.1 | GitHub |
| MT-DNN | GLUE | GLUE | GitHub |
Dịch lược từ Tác giả Michael Balaban